お客様の課題に応じて、専門のリサーチャーが最適な集計/分析手法をご提案します。
また、当社がご提供する簡易集計ツール「Speed CROSS 3」を利用して、お客様ご自身が集計表作成やレポート作成等を行うことも可能です。
- テキストマイニングツール
テキストマイニング(TextVoice) - 集計ツール
Speed CROSS(スピードクロス)
集計手法
- 単純集計
単純集計とは、回答者全員の回答結果を集計する手法です。ある選択をした回答者の割合が一覧できる、最も基本的な集計手法となります。
下記のQ2の単純集計では、「加入しており、現在の会社との契約を継続したい」 と答えた人が最も多くなっていることがわかります。
単純集計の結果をレポートする場合、集計対象者が調査目的を上手く反映しているかどうか注意する必要があります。 例えば、関東地区におけるある商品の認知率を知りたい場合、集計対象者は関東地区の全員から無作為に抽出する必要があります。 しかし、完全な無作為抽出が難しい場合、性別・年齢階層等可能な範囲で回収数の分布が現実の値に近くなるように回収数を割り当て、出来る限り実態を反映した値になるように事前に回収計画をたてる必要があります。
- クロス集計
クロス集計とは、回答データに属性(性別や年代)などをかけあわせて集計する手法です。
例えば、男性と女性で回答傾向に違いがあるか確認したいとき、男女別のクロス集計を行うことで男女間の違いを比較することができます。
下記の集計を、「男女(性別)を集計軸としたクロス集計」と呼びます。下記の例では、男性と女性では回答傾向に大きな違いは見られません。
男女別以外にも、年齢別や居住地域別等の属性や、アンケートの回答内容を集計軸としてクロス集計を行うことで、より詳細に回答傾向を把握します。それによって仮説を検証し、新たな知見を得ることができます。集計軸として、下記のような人口構成的(デモグラフィック)属性だけでなく、心理、態度、行動、求めるベネフィット、重視する点、その他実態設問項目等を用いることで、より広い視野から生活者の理解を深めることもできます。
また、属性や設問を組み合わせて新たな集計軸を作成したり、複数の集計軸を組み合わせて(多重クロス集計)より詳細な分析をしたり、細かなセグメントごとに傾向を把握することもできます。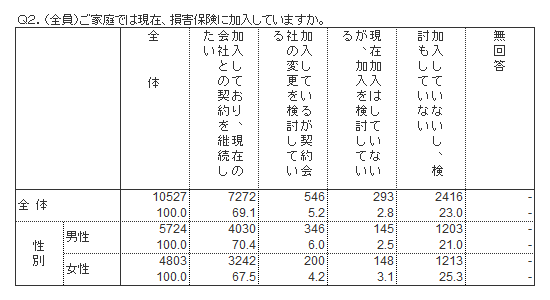
- ウェイトバック集計
- 小計追加、変数加工、新変数の作成、ウェイトバック集計(ネットリサーチ用語集)等も可能です。
分析手法
- 相関係数
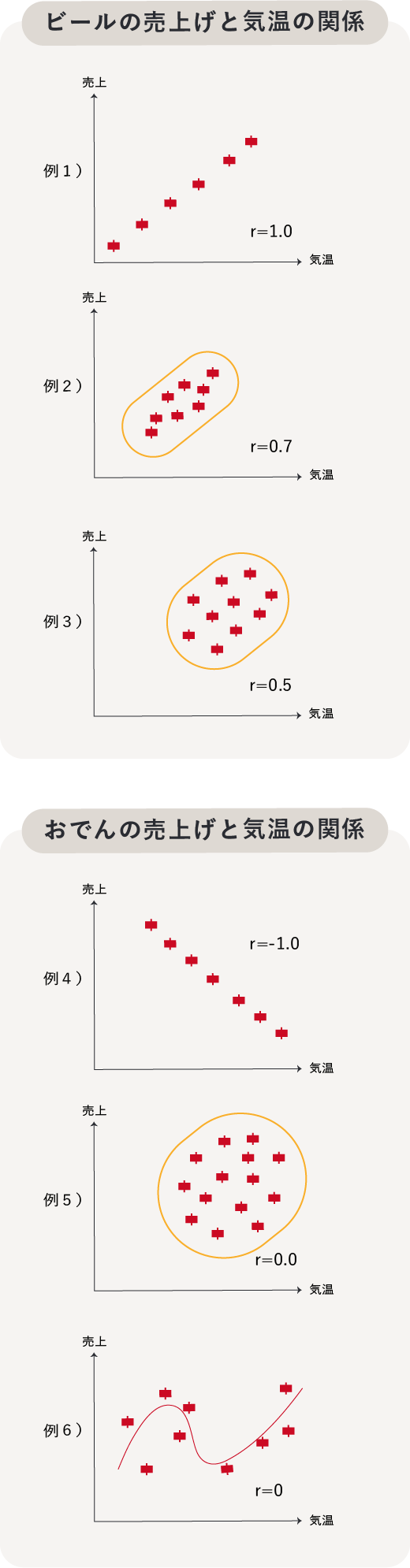
相関係数とは、2つのデータにある関係の強さを測る指標を用いて分析する手法です。-1〜1の数値となりますが、0に近づくほど関係が弱く、-1または1に近いほど関係が強いことを示します。
例えば「例1.ビールの売上げと気温の関係」のように気温が高いほど、売上げも高くなっている場合、正の相関関係がある、と言います。(逆に、「例4.おでんの売上げと気温」のように気温が高いほど売上げが下がっている場合は、負の相関関係がある、と言います。)
例6のように、明らかに関係が見られても、その関係が直線的でない場合はうまく関係性を測れない(=相関係数が小さい)場合があります。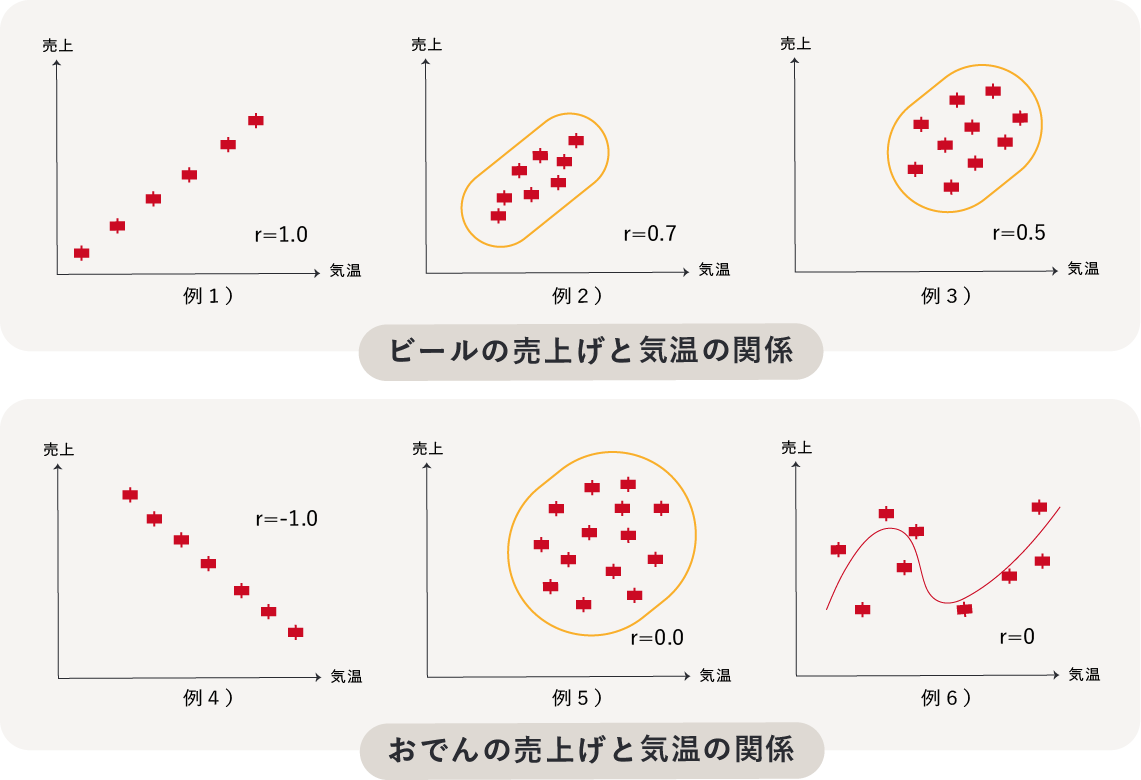
- 回帰分析
-
回帰分析とはあるデータ(変数)と、ひとつ以上の別データ(変数)との関係をみる手法のことです。
下記の例では、データYとデータX、Zの関係を見ています。αは一定の値をとる「定数項」、βはXとYの関係を示すXの回帰係数、γはZとYの関係を示すZの回帰係数と呼ばれるものです。回帰係数は、それぞれの説明変数のデータが変化したとき、被説明変数のデータがどの程度変化するのか表しています。
下記のような回帰式は、データYをデータX等で予測したい場合や、データYにどのような要因が影響を与えているか知りたいとき等に利用することができます。

- 因子分析
-
因子分析とはアンケート等のデータの背後にある、潜在的な要因(因子)を明らかにする手法です。 下記の例では、回答の背後に2つの因子があることがわかります。
<具体的な手順>- 因子分析に用いる項目を選ぶ
- 因子の数を決める
- 各因子と項目の関係(因子負荷量)を見ながら各因子を解釈し、適切な名前をつける
アンケート項目が多数ある場合等、全体として回答に影響している要因がわかりづらくなることがあります。そのような場合に同様の傾向を持つ項目をまとめ、結果が意味するところを把握する方法としても利用できます。


- クラスター分析
-
クラスター分析とは回答データの回答者や選択肢を、類似した傾向を持つグループに分類する手法です。クロス集計等では把握しづらい"隠れた"グループに分け、潜在的なセグメントを把握することができます。
下記例は階層クラスター分析で「利用したい会社」をグループ分けした結果です。大まかに見ると、A〜D社とE〜G社のグループに分かれることがわかります。
クラスター分析で明らかとなったセグメントを集計軸としたクロス集計を行うことで、より広く、深い生活者の理解ができます。 また、アンケートの設問や選択肢等をクラスター分析でグループ化することで、独自の評価指標を作成することもできます。その他、生活者の意識をより深堀するために因子分析との組み合わせもよく行われます。
- コレスポンデンス分析
-
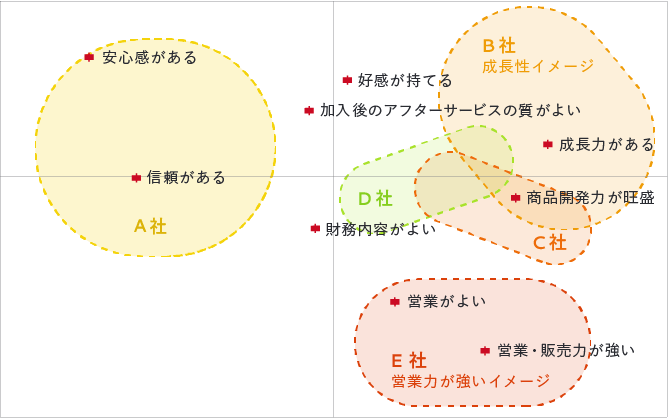
コレスポンデンス分析は、クロス集計等の集計結果をより視覚的に把握するための手法です。関連性が強いものは近くに、弱いものは離れて配置されます。
例えば、下記例では生命保険会社ごとのイメージを比較した集計を元にしてコレスポンデンス分析を行っています。結果をみると、A社は「安心感がある」「信頼がある」に近く、また、E社は「営業がよい」「営業・販売力が強い」の近くに配置されています。A社は<安心・信頼>のイメージが強く、E社<営業力が強い>イメージが強いことが視覚的にわかります。
ブランドイメージの比較やポジショニング確認、項目が多く集計表や通常のグラフからは結果が読み取りづらいとき等にご活用いただけます。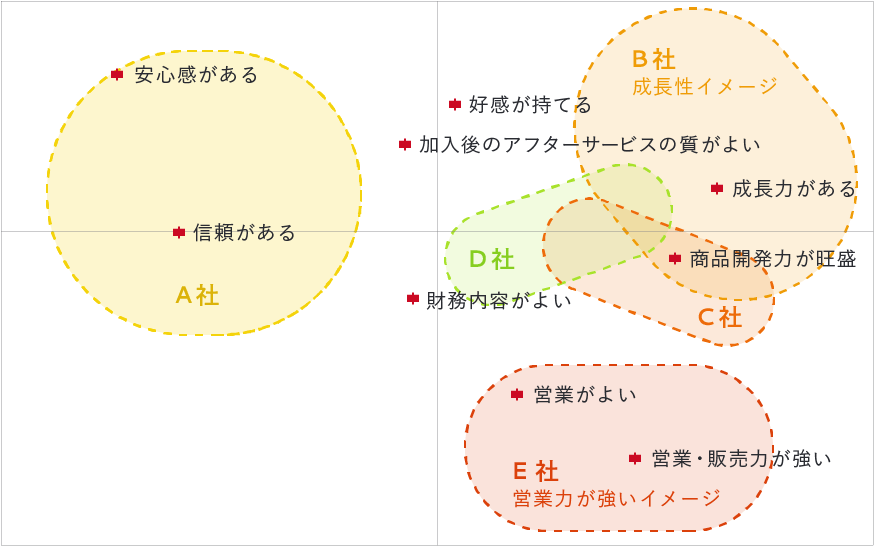
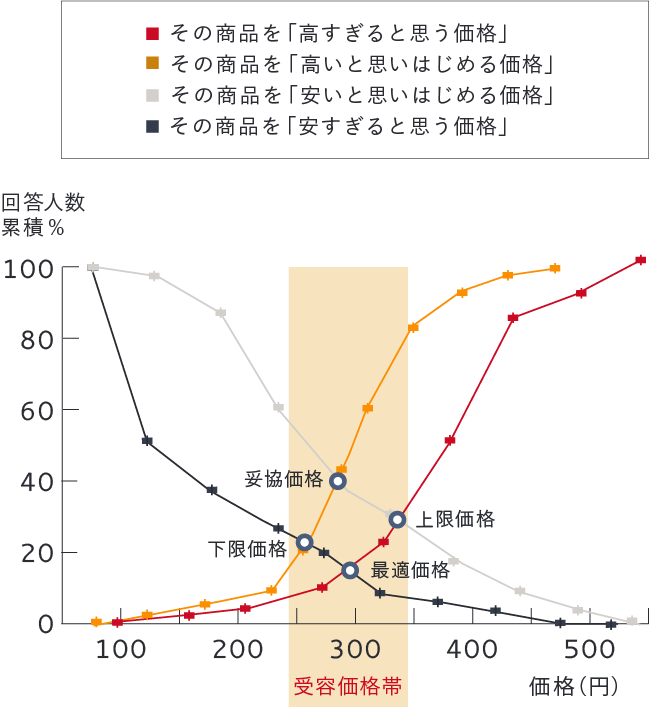
- PSM分析
-
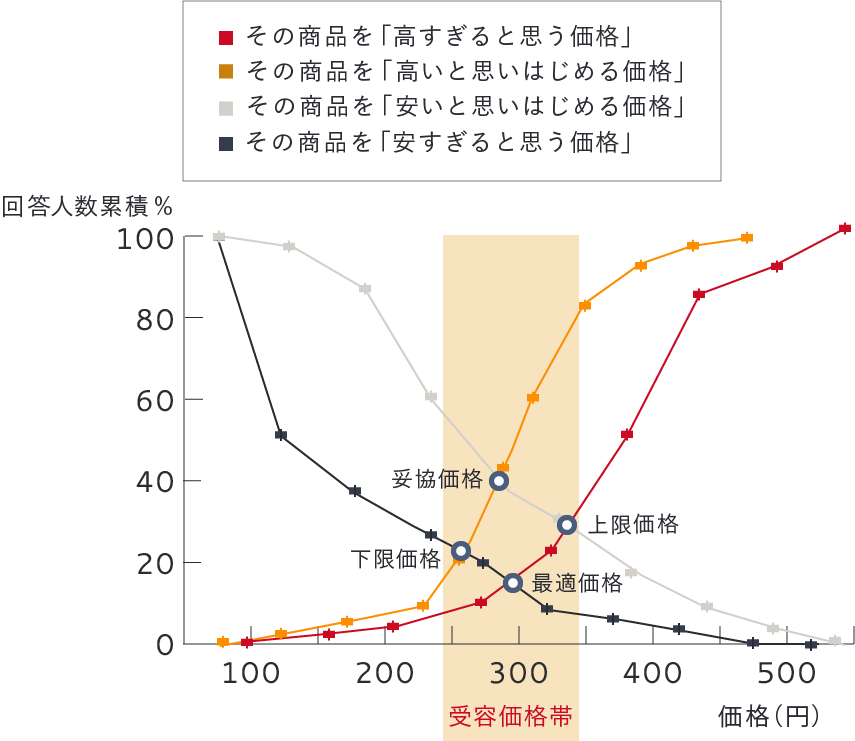
PSM分析は、商品の価格について4つの質問をすることで、生活者の持つ「価格感」を把握する手法です。
- 【設問1】 その商品が「高すぎると思う価格」
- 【設問2】 その商品が「高いと思いはじめる価格」
- 【設問3】 その商品が「安いと思いはじめる価格」
- 【設問4】 その商品が「安すぎると思う価格」
以上の4つの設問を集計した結果を下記のようなグラフにし、生活者の価格感、価格受容性をつかみます。
分析ツール
- テキストマイニング
- テキストマイニングとは、大量のテキストデータを解析し情報を取り出す手法です。
昨今のインターネット調査では大量の自由回答を回収できるようになりました。しかし、それらを読み込むだけでは全体の特徴や傾向が把握できないため、テキストマイニングで分析することが増えています。
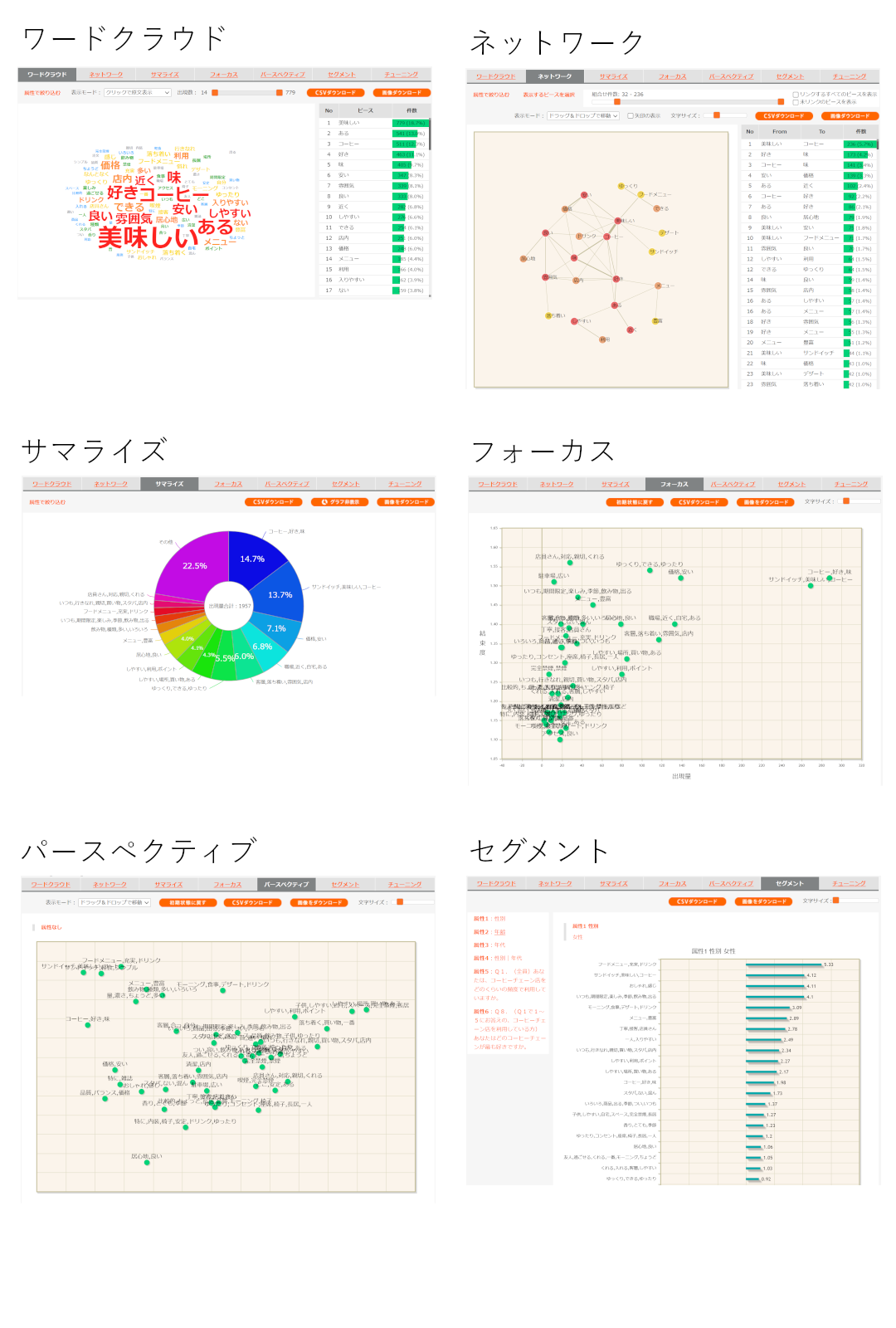
当社では、独自のテキストマイニング・ツール(TextVoice)を使った分析を提供しています。
テキストマイニング・ツール(TextVoice)の6つのアウトプット- ワードクラウド:言葉の出現量でランキングします。
- ネットワーク:2語のつながりでランキングします。
- サマライズ:最大6語の組合せでランキングします。
- フォーカス:少数でも、注目すべき意見を確認します。
- パースペクティブ:似た意見をグループ化します。
- セグメント:属性による特徴を確認します。